Reinforcement Learning
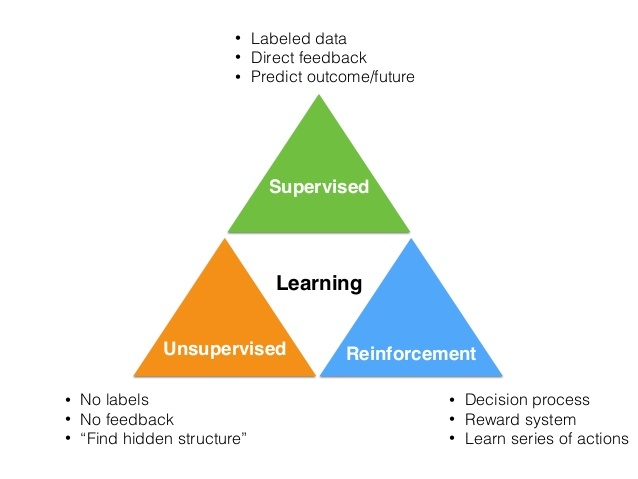
- 特点
- 试错学习:强化学习一般没有直接的指导信息,Agent要以不断与Environment进行交互,通过试错的方式来获得最佳策略(Policy)
- 延迟回报:强化学习的指导信息很少,而且往往是在事后(最后一个状态(State))才给出的
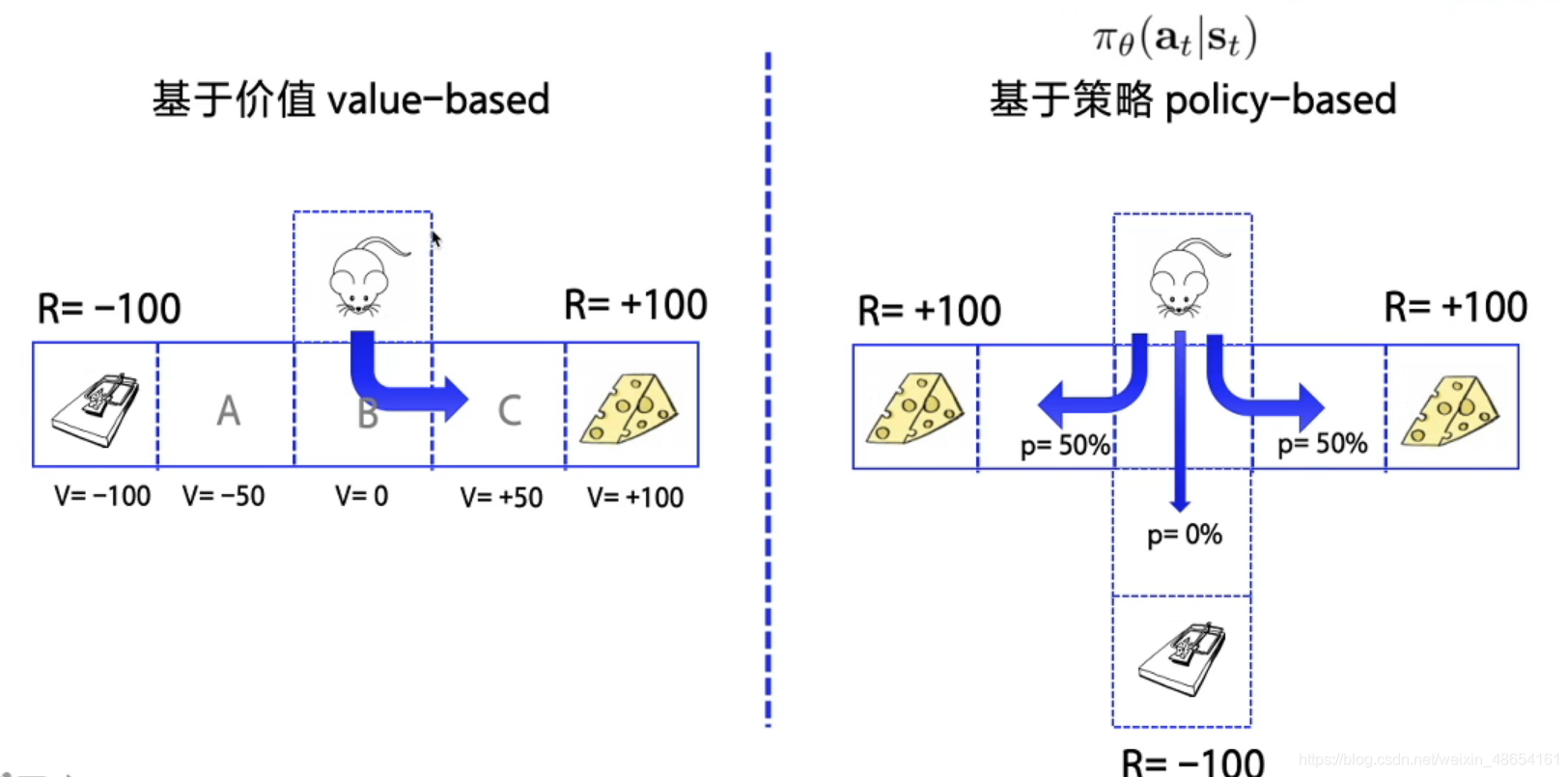
Policy-Based And Value-Based
- Policy-Based的方法直接输出下一步动作的概率,根据概率来选取动作。但不一定概率最高就会选择该动作,还是会从整体进行考虑。适用于非连续和连续的动作
- Value-Based的方法输出的是动作的价值,选择价值最高的动作。适用于非连续的动作
- 两者结合,Actor根据概率做出动作,之后根据动作给出价值,从而加速学习过程
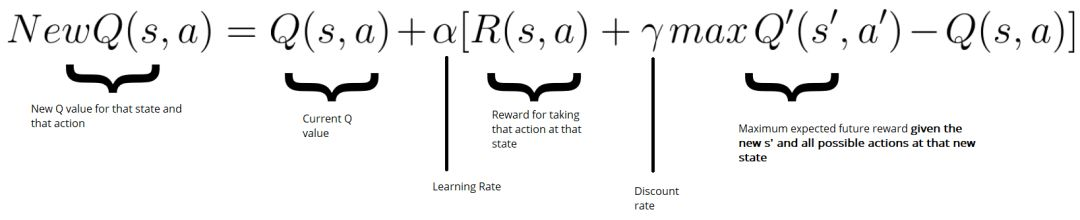
Q-Learning
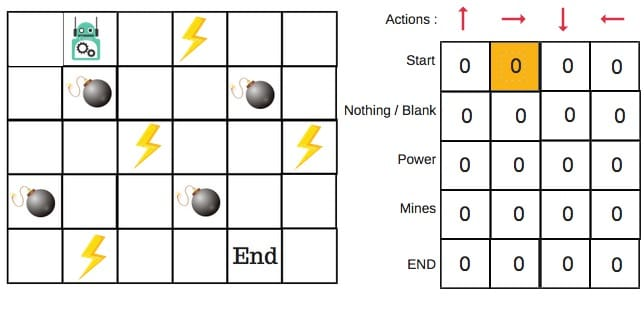
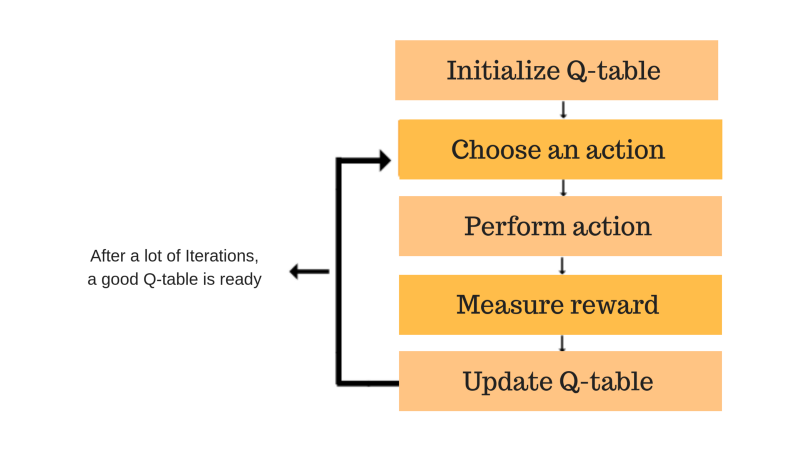
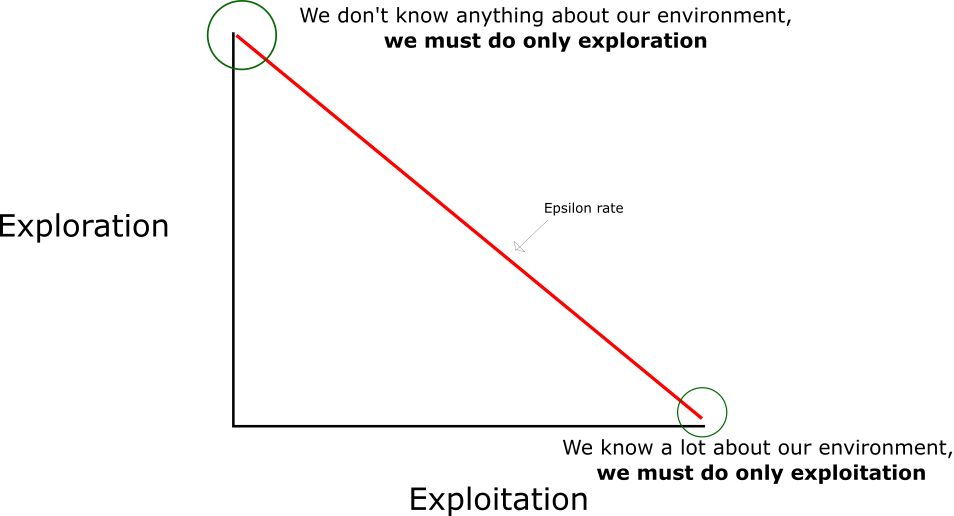
Explore & Exploit
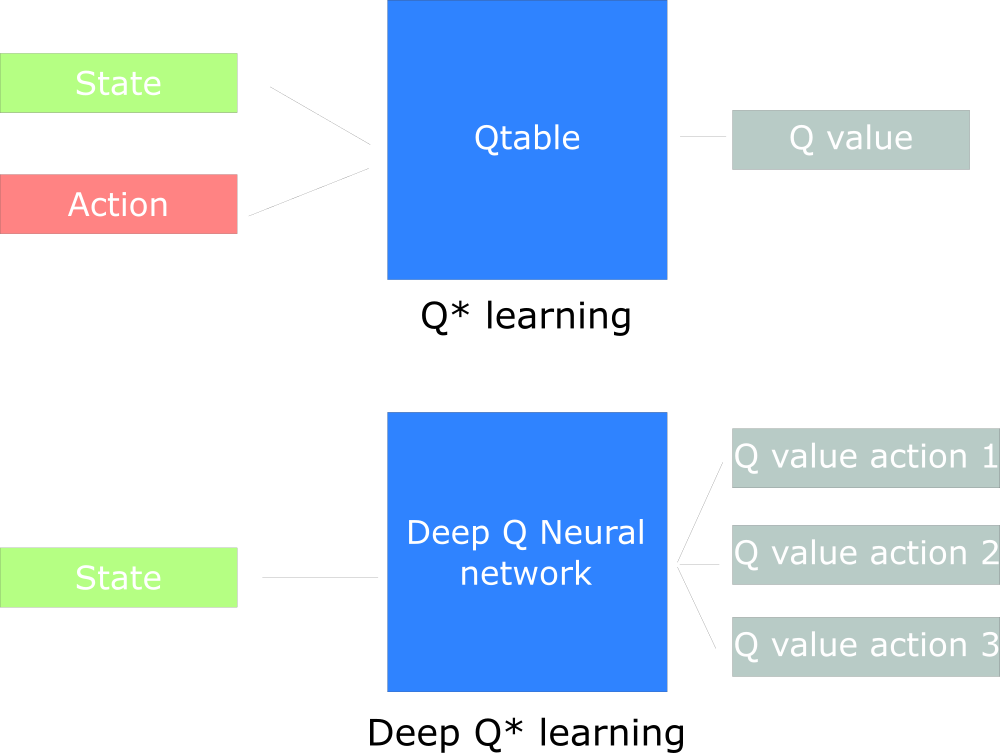
Deep Q Network (DQN)
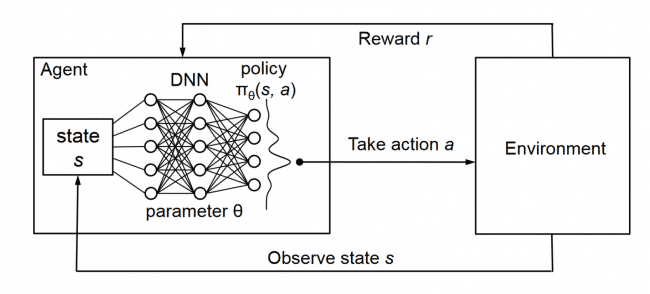
Deep Q Network
Deep Q Network的损失函数


