Recent Advances on Federated Learning: A Systematic Survey(2023) + Machine Learning
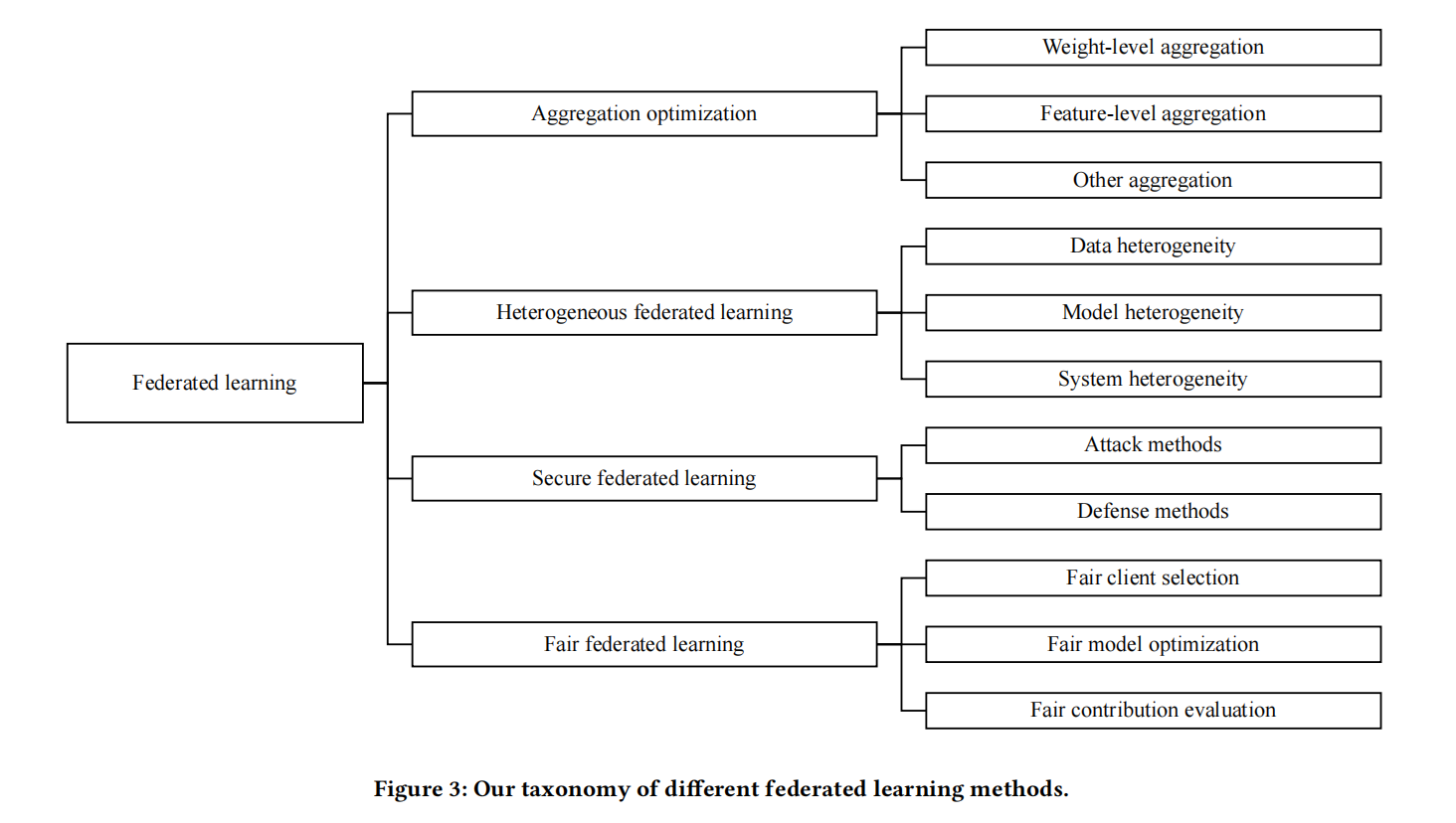
联邦学习研究的分类
聚合算法的权重分配研究(FedAvg是其中之一)
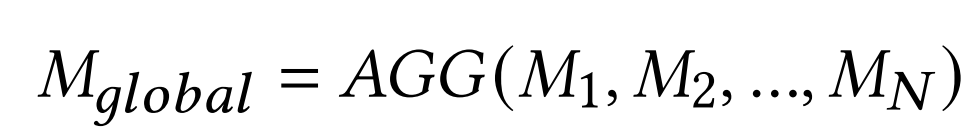
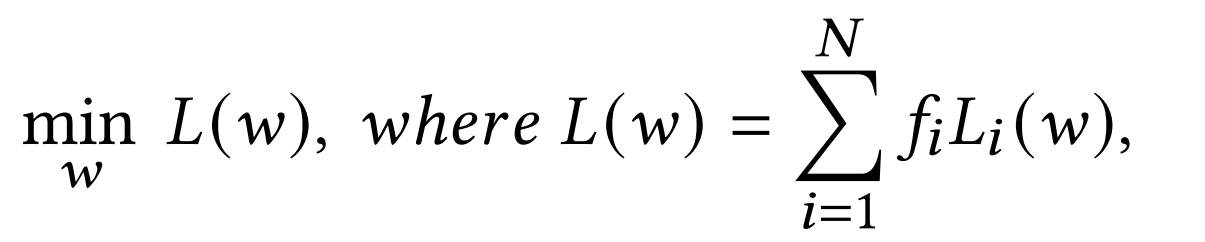

动态联邦学习研究
- 当前的联邦学习方法假设每个客户端中的数据是稳定不变的。然而,在现实世界的场景中,客户端可能处于一个不断变化的环境中,其中本地数据持续被传感器观察和处理。在这种条件下,直接进行传统的训练和聚合将遭受灾难性遗忘问题,即模型可能会随着新数据的到来而忘记之前学到的知识。增量学习是一个热门的研究主题,目标是在维持识别之前知识的能力的同时学习新知识。将来,如何有效地结合联邦学习和增量学习值得探讨。
- Incremental learning with neural networks for computer vision: a survey
去中心化的联邦学习研究
- 中央服务器对传统联邦学习至关重要,因为需要在此进行聚合。考虑到第三方服务器可能不诚实,将参数或梯度上传到它可能存在安全风险。因此有必要实现没有服务器参与的联邦学习。尽管He等人已经对去中心化的FL做了初步的尝试,但他们只针对逻辑回归,并且实验不足。如何实现一般的去中心化FL仍然是一个悬而未决的问题。
联邦学习的可扩展性研究
- 最近的FL论文更多地关注设计新算法以改进不同条件下的FL性能。然而,它们忽略了可扩展性属性,这决定了我们是否能够进行大规模的FL。在许多合作场景中,可能有大量的参与方,我们应该在参与者数量增加时为合作改进提供指导。总之,FL的可扩展性值得未来的研究。
统一基准研究
- 尽管已经使用了大量的数据集来评估FL的性能,但仍然缺乏一个统一的基准来对齐结果以进行公平比较。一方面,为了实现不同的联邦目标(例如,个性化,鲁棒性),研究人员使用不同的数据集来测试性能。另一方面,不同FL也应用了不同的数据集来展示不同FL类型的性能。
Neural Networks
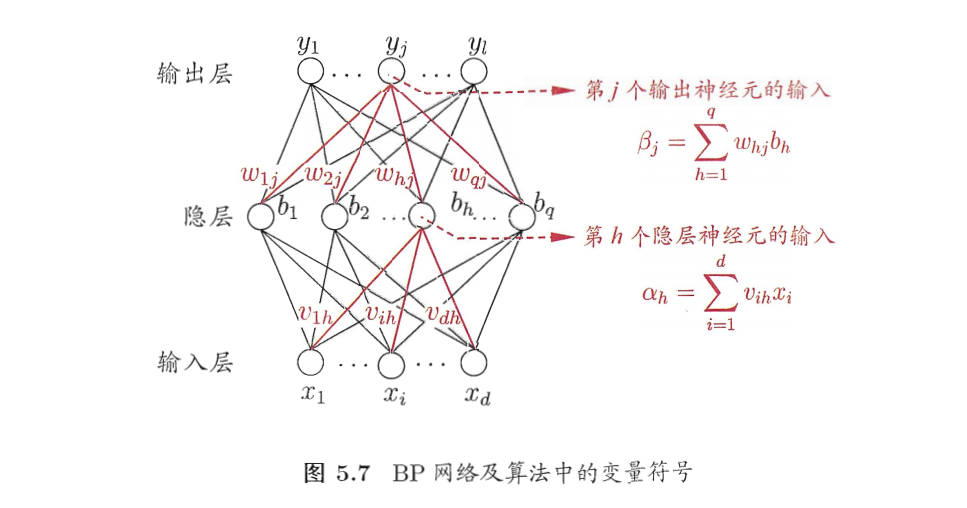
多层感知机 Multilayer Perceptron MLP
- 每层神经元与下一层神经元全互连,神经元之间不存在同层连接,也不存在跨层连接.这样的神经网络结构通常称为“多层前馈神经网络” (multi-layer feedforward neural networks),其中输入层神经元接收外界输入,隐层与输出层神经元对信号进行加工,最终结果由输出层神经元输出;换言之,输入层神经元仅是接受输入,不进行函数处理,隐层与输出层包含功能神经元。 神经网络的学习过程,就是根据训练数据来调整神经元之间的“连接权” (connection weight)以及每个功能神经元的阈值;换言之,神经网络 “学”到的东西,蕴涵在连接权与阈值中。
反向传播算法





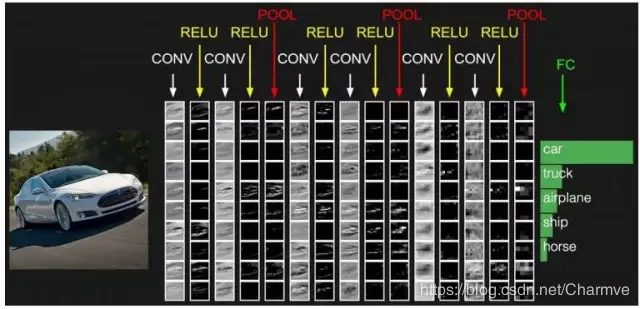
卷积神经网络
- 一个卷积神经网络主要由以下5层组成
- 数据输入层
- 卷积计算层
- ReLU激励层
- 池化层
- 全连接层
Resnet(Residual Network),残差网络
Deep Residual Learning for Image Recognition, CVPR2016最佳论文
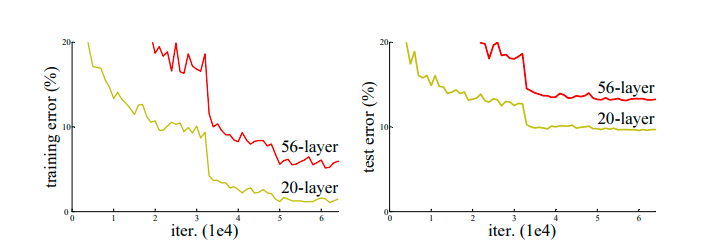
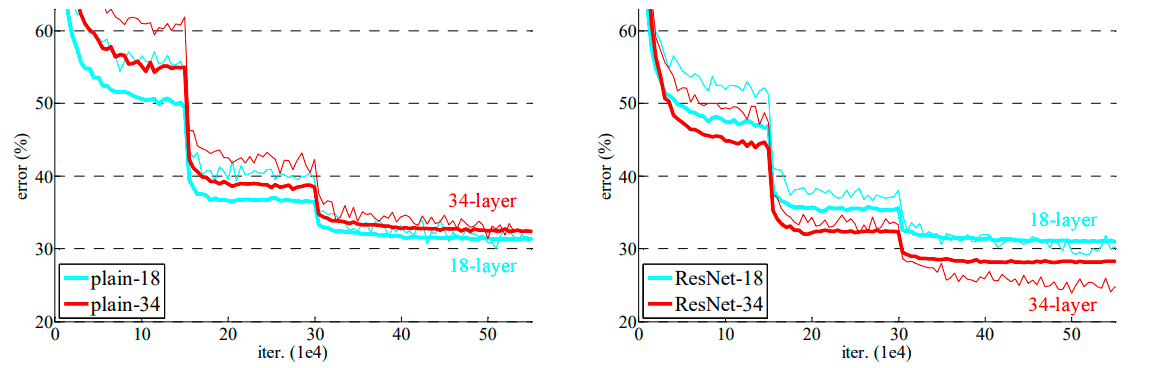
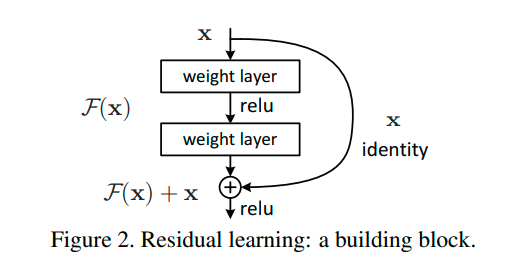
ResNet
- 短路连接(Shortcut Connections): 残差学习的核心是引入短路连接,也叫作残差连接。这种连接允许输入数据绕过一个或多个网络层,直接到达更深的层。这种结构有助于网络学习恒等映射,从而使得增加网络深度不会影响模型的性能。
- 解决梯度消失和爆炸问题: 在深度神经网络中,梯度消失和梯度爆炸是常见问题。通过残差学习,网络能够保持梯度的正常流动,从而避免这些问题。 增加网络深度: 由于残差学习解决了梯度消失和爆炸问题,因此可以构建更深的神经网络,从而提高模型的性能。
- 残差学习是通过残差网络(ResNet)实现的,ResNet是于2015年提出的。残差网络通过引入残差模块,使得网络能够学习输入和输出之间的残差,而不是直接学习输出。通过这种方式,网络可以很容易地学习恒等映射,从而使得网络能够通过增加深度来提高性能。
Vanishing Gradient and Exploding Gradient
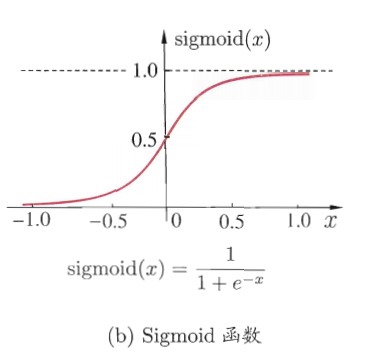
- 梯度消失:在神经网络训练的反向传播过程中,梯度是通过链式法则从输出层向输入层传播的。如果网络很深,且激活函数及其导数的值较小,例如使用Sigmoid激活函数,那么在反向传播过程中梯度的值会随着每层的传播而变得越来越小。当梯度变得非常小,接近于零时,权重更新将变得微不足道,导致网络学习非常缓慢或完全停止学习。这种情况下,网络的权重几乎不会有任何变化,使得网络不能够良好地学习或优化。
- 梯度爆炸:梯度爆炸与梯度消失相反,它是指在反向传播过程中,梯度的值变得非常大,以至于导致权重更新非常剧烈。如果网络的梯度变得过大,那么在权重更新时会产生很大的步长,导致网络权重在优化空间中大幅震荡,甚至可能导致网络完全失去学习能力。
- 解决方法:选择适当的激活函数,如ReLU及其变体。使用残差网络(ResNet)结构,通过残差连接来促进梯度的传播。适当地初始化网络权重。